1. Why AI and Machine Learning matter now
AI and ML move from experiments into production. Companies deploy models in user-facing systems. For example, recommendations, fraud detection, and medical imaging inference run live. Because of this shift, businesses need talent that can deliver reproducible, scalable solutions.
- Data volumes are massive. Therefore, models trained on larger data give better results.
- Cloud and GPUs are cheaper. Thus deep learning at scale is feasible.
- Open-source models and preprints accelerate innovation. For example, transfer learning and transformers cut training time.
- Regulation and ethics matter more. Consequently, companies hire experts who can audit models and explain decisions.
Result: demand for engineers who know algorithms and systems engineering has risen sharply. Recruiters prefer practical experience. Hence, projects and deployment skills matter.
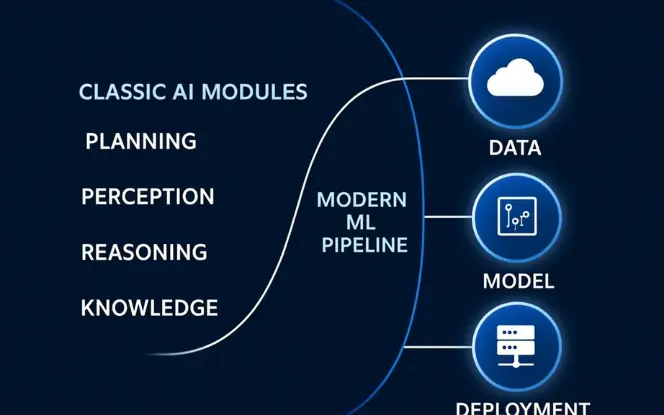
2. What AI and Machine Learning actually do
AI is the umbrella. AI covers rule-based systems, symbolic logic, planning, and learning. ML is a subset. ML builds models that learn from data.
Key technical distinction
- AI (broad): systems that act intelligently. This includes expert systems and planning algorithms.
- ML (narrow): models that infer functions from examples. They rely on statistical learning theory.
Concrete examples, technically explained
- Classification (ML): map input xxx to label yyy. Use logistic regression or neural nets. Evaluate with accuracy, F1, ROC-AUC.
- Regression (ML): predict continuous yyy. Use linear models or boosted trees. Metrics: RMSE, MAE, R2R^2R2.
- Reinforcement Learning (AI/ML): learn policy π(a∣s)\pi(a|s)π(a∣s) to maximize expected reward. Algorithms: Q-learning, Policy Gradient.
NLP (AI/ML): tokenization → embeddings → transformer encoder/decoder. Pretraining objectives like MLM or autoregressive training power performance.
3. Core skills
This section lists required knowledge and explains why each item matters. Each skill includes concrete ways to practice.
3.1 Mathematics & Statistics
You must read math with an applied focus.
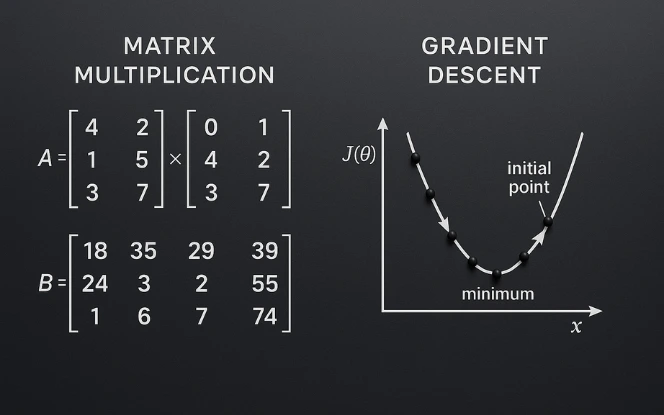
- Linear algebra: vectors, matrices, eigenvalues, SVD. Why? Neural networks, PCA, and embeddings use these.
Practice: implement matrix multiply, SVD, and PCA from scratch in Python. - Probability: random variables, conditional probability, Bayes’ theorem. Use it to handle uncertainty.
Practice: derive likelihoods for simple models. - Calculus: gradients, chain rule, partial derivatives. This underlies backpropagation.
Practice: compute gradients for a simple 2-layer network on paper. - Optimization: SGD, mini-batch, momentum, Adam. Understand learning rates and convergence.
Practice: tune learning rate and batch size; plot training loss curves. - Statistics: bias-variance tradeoff, hypothesis testing, confidence intervals. Use these to validate models.
Practice: run A/B tests and compute p-values on sample data.
3.2 Programming & Software Engineering
You need clean code and reproducible experiments.
- Languages: Python is primary. R can be useful for statistics.
- Libraries: NumPy, Pandas (data), Scikit-Learn (baseline models), Matplotlib/Seaborn (plots). For deep learning: PyTorch and TensorFlow.
- Coding practice: write modular code. Use functions, classes, and unit tests.
- Version control: Git. Use branches, pull requests, and code reviews.
- Code quality: linters, type hints, CI pipelines.
Practice task: set up a GitHub repo with notebooks and scripts. Add unit tests for data transforms.
3.3 Data Handling & Feature Engineering
Data wins or fails projects.
- Data ingestion: read from CSV, databases, APIs. Use chunking for large files.
- Cleaning: handle missing values, outliers, and inconsistent types. Use imputation strategies.
- Feature engineering: construct new features. For time series, create lags, rolling stats. For text, build TF-IDF or embeddings.
- Scaling & encoding: StandardScaler, MinMaxScaler, one-hot, ordinal encoding. Know when to use each.
- Pipelines: create preprocessing pipelines using Scikit-Learn or custom functions.
Practice task: build a full preprocessing pipeline. Persist it with joblib or ONNX.
3.4 Machine Learning Algorithms
Know algorithm internals and when to use them.
- Linear / Logistic Regression: baseline, explainable, fast. Use L1/L2 regularization.
- Tree models: decision trees, Random Forests, XGBoost, LightGBM. Good for tabular data and feature importance.
- SVMs: useful for medium-sized datasets, kernel tricks for non-linear separation.
- k-means / clustering: unsupervised grouping. Evaluate with silhouette score.
- Ensembles / stacking: combine models to improve performance.
Model selection: validate with cross-validation. Use stratified splits for imbalanced classes. Monitor leakage.
3.5 Deep Learning — architectures and tradeoffs
Go beyond “use a library” and understand design choices.
- Feedforward nets: baseline for regression/classification. Choose width/depth carefully.
- CNNs: convolution, pooling, receptive fields. Use for images and spatial data.
- RNNs / LSTM / GRU: sequence modeling. Transformers have largely supplanted them for long sequences.
- Transformers: self-attention, positional encoding, multi-head attention. The backbone of modern NLP and vision models.
- Generative models: VAEs, GANs, and diffusion models. Use them for synthesis and augmentation.
- Loss functions: cross-entropy for classification, MSE for regression, BCE for multi-label.
- Regularization: dropout, weight decay, batchnorm, data augmentation.
Practice task: implement a small CNN in PyTorch. Train on CIFAR-10 and report metrics.
3.6 MLOps & Productionization
Models must work in production.
- Model serving: Flask/FastAPI, TorchServe, TensorFlow Serving. Choose based on latency needs.
- Containerization: Docker images for consistent runtime.
- CI/CD for ML: automate training, testing, and deployment. Use pipelines to retrain models on schedule.
- Monitoring: log latency, throughput, and model drift metrics. Use Prometheus or cloud tooling.
- Feature store: central repository for features to ensure consistency between training and serving.
Data versioning: DVC or Delta Lake to track datasets.

4. Tools, platforms, and system architecture
Local to cloud progression
- Local: Jupyter, Conda, virtualenv, CPU/GPU with CUDA drivers.
- Cloud: AWS (SageMaker, EC2, S3), GCP (AI Platform, BigQuery), Azure ML.
- Experiment tracking: MLflow, Weights & Biases.
- Data storage: relational DBs, object storage for large files, data warehouses for analytics. Use columnar formats like Parquet.
Distributed training: Horovod or native framework options. Use when dataset or model is large.

5. Career path — roles, sample tasks, KPIs
I’ll expand each role with technical tasks and measurable KPIs.
5.1 AI / ML Intern
Tasks: data cleaning, baseline models, simple EDA.
KPIs: reproducible notebooks, PR reviews, unit test coverage.
Technical growth: learn version control and basic model metrics.
5.2 Junior ML Engineer
Tasks: implement pipelines, tune models, write tests.
KPIs: model accuracy improvements, training time reduction, reproducible pipeline.
Skills to show: feature engineering, basic deployment.
5.3 ML Engineer
Tasks: productionize models, build APIs, optimize inference.
KPIs: latency, throughput, uptime, model performance in production.
Skills to show: model serving, monitoring, retraining strategies.
5.4 Data Scientist
Tasks: design experiments, produce business insights, build models for decisioning.
KPIs: impact on business metric (e.g., conversion lift), model explainability.
Skills to show: causal analysis, robust A/B testing.
5.5 Senior ML / AI Engineer
Tasks: design system architecture, mentor juniors, own ML lifecycle.
KPIs: system reliability, team velocity, production incident rate.
Skills to show: architecture design, cost optimization.
5.6 Research Engineer
Tasks: prototype new algorithms, publish papers, evaluate SOTA methods.
KPIs: papers, open-source contributions, experiments showing improvement.
Skills to show: math rigor and experimental reproducibility.
6. Industry applications
Healthcare (medical imaging)
● Data: DICOM images, metadata.
● Pipeline: preprocessing → segmentation → classification → validation.
● Tech: CNNs, transfer learning, explainability methods (Grad-CAM).
● Regulatory: audit trails, data privacy (HIPAA/GDPR).
● Outcome: disease detection, triage automation.
Finance (fraud detection)
● Data: transactions, behavioral logs.
● Pipeline: feature engineering → anomaly detection → model base rates.
● Tech: gradient boosting, autoencoders for anomalies.
● Constraints: low false positives, latency requirements.
● Outcome: reduce fraud losses with high precision.
E-commerce (recommendation systems)
● Data: user interactions, product catalogs.
● Pipeline: candidate generation → ranking → online evaluation.
● Tech: collaborative filtering, matrix factorization, deep ranking networks.
● Metric: click-through rate, conversion rate lift.
Autonomous systems (robotics)
● Data: sensors, LIDAR, images.
● Pipeline: perception → localization → planning → control.
● Tech: sensor fusion, RL for policy learning.
7. Salary expectations and levers to increase pay
Salaries vary by skill and impact. Key levers that increase pay:
● Impact: projects that save money or increase revenue.
● Specialization: deep learning, transformers, or production MLOps.
● Experience: demonstrable deployments and leadership.
● Geography and company: metropolitan hubs and tech firms often pay more.
● Open source and papers: public work signals expertise.
Tip: document impact in numbers. For example, “improved CTR by 3.4%” is stronger than
“improved engagement.”
8. Learning path — timeline, weekly plan, and milestones
I’ll give a 6-12 month practical roadmap for someone starting from scratch.
Month 0–1: Foundations
● Learn Python. Focus on lists, dicts, functions, and I/O.
● Practice: solve small exercises on HackerRank.
● Milestone: complete 10 small scripts and one mini data task.
Month 2–3: Data and Statistics
● Learn Pandas and basic SQL.
● Learn statistics and EDA.
● Practice: clean a real dataset and produce an EDA report.
● Milestone: publish EDA notebook to GitHub.
Month 4–6: Core ML
● Learn Scikit-Learn models. Implement regression, classification, and clustering.
● Start small projects: Titanic, House Prices.
● Milestone: one deployable model with a simple API.
Month 7–9: Deep Learning & NLP
● Learn PyTorch/TensorFlow basics. Build CNN and RNN models.
● Explore transformers and fine-tuning.
● Milestone: train a transformer on a small text dataset and evaluate.
Month 10–12: Production Skills & Specialization
● Learn Docker, serving, and monitoring.
● Work on MLOps pipelines.
● Milestone: production-grade deployment with CI/CD.
Weekly routine suggestion: 5–10 hours weekly. Allocate time to reading, coding, and
projects.

9. Project recipes — step-by-step
Project A: House Price Prediction (tabular model)
Goal: predict house prices using tabular features.
Steps:
1. Data: load CSV with Pandas. Inspect missing values.
2. EDA: visualize distributions, correlations.
3. Preprocess: impute missing values, encode categoricals, scale numeric features.
4. Baseline: train Linear Regression and log-transform target if skewed.
5. Advanced: train XGBoost/LightGBM with hyperparameter tuning (GridSearch or
Optuna).
6. Validation: k-fold cross-validation, keep a holdout test set.
7. Explain: SHAP values for feature importance.
8. Deploy: export model with joblib; serve via FastAPI in Docker Project B: Sentiment Analysis Chatbot (NLP)
Goal: build a sentiment model and simple chatbot.
Steps:
1. Data: collect tweets or reviews. Clean text (lowercase, remove URLs).
2. Tokenize: use HuggingFace tokenizer.
3. Model: fine-tune a transformer (e.g., BERT) for classification.
4. Evaluation: use F1, precision, and recall due to class imbalance.
5. Inference: create a small API for predictions.
6. Chat: integrate the model with a simple rule-based dialog manager.
7. Deploy: use TorchServe or FastAPI with a worker pool.
10. Interview prep, portfolio, and hiring signals
What recruiters look for (technical signals)
● Reproducible code: notebooks with README and run scripts.
● End-to-end projects: data ingestion to deployment.
● Model metrics and baselines: show lift over baseline.
● Production knowledge: Docker, serving, monitoring.
● Communication: explain tradeoffs, model behavior, and edge cases.
Portfolio checklist
● GitHub repo per project.
● Short blog post describing problem and approach.
● Live demo or recorded walkthrough.
● Metrics and ablation study.
● Clear instructions to run the project locally.
Interview topics to prepare
● Coding: data structures, algorithms, and complexity.
● ML theory: bias-variance, overfitting, regularization.
● Modeling: choose algorithm and explain rationale.
● System design: design a recommendation system or real-time inference service.
● Behavioral: describe impact and failure cases.
Practice method: run mock interviews. Record answers. Improve clarity. .

11. Certifications, research, and continued learning.
Certifications worth considering
● Vendor cloud certs: AWS ML Specialty, Azure AI Engineer.
● Practical certs: TensorFlow Developer Certificate.
● University micro-credentials: verified courses from top universities.
Research and open source
● Contribute to libraries or datasets.
● Reproduce recent papers. Write short technical blogs on findings.
● Attend conferences and local meetups.
Continuous learning habits
● Read arXiv alerts weekly.
● Follow model cards and datasheets for responsible ML.
● Participate in Kaggle competitions for practical feedback.
12. FAQs
Q: Do I need a degree?
No. However, a degree helps for research roles. Practical skills matter more for engineering
roles.
Q: Which language to learn first?
Python. It has the largest ecosystem for ML.
Q: How much math is required?
Applied math is required. Deep theoretical math is only needed for research
Q: How long to become job-ready?
With focused effort, 6–12 months for entry roles. Real-world projects speed hiring.
Q: Should I learn cloud early?
Yes. Learn basic cloud deployment alongside models